Wie finden Unternehmen die Balance zwischen strikter Compliance und globaler Wettbewerbsfähigkeit?

Siehe hierzu auch:
Drahtseilakt – Die EU zwischen Ethik und Innovation
EU will KI stärker regulieren

TechToons
Cartoons zu Datenschutz: Einwilligung, Datenerhebung und -nutzung, Cookies/Tracking und Transparenz in Alltag und Organisation.
Wie finden Unternehmen die Balance zwischen strikter Compliance und globaler Wettbewerbsfähigkeit?
Siehe hierzu auch:
Drahtseilakt – Die EU zwischen Ethik und Innovation
EU will KI stärker regulieren
Künstliche Intelligenz ist kein neutraler Beobachter, sondern ein Spiegel ihrer Trainingsdaten. Wenn die Datenbasis aus einer sozialen Echokammer stammt, spuckt der Algorithmus am Ende nur unsere eigenen Vorurteile wieder aus.

Siehe auch:
Automation Bias
Künstliche Intelligenz entsteht nicht aus dem Nichts.
Sie fußt auf drei tragenden Säulen: der massenhaften Sammlung von Daten, der unsichtbaren Arbeit zahlloser Menschen – oft unter prekären Bedingungen – und der Ausbeutung enormer materieller Ressourcen.
Häufig wird sie mit magischen oder wundersamen Eigenschaften versehen, als handle es sich um eine körperlose Intelligenz. Hinter der glatten Oberfläche von „intelligenten“ Anwendungen verbirgt sich ein globales Netz aus Überwachung, menschlicher Klickarbeit, Energieverbrauch und Ressourcenabbau.
Vgl. Kate Crawford (2021): Atlas of AI. Yale University Press. Siehe auch Crawford & Joler (2018): Anatomy of an AI System.

Bei der Einführung von KI stoßen Unternehmen oft auf mehr Hindernisse, als es auf den ersten Blick scheint. Neben technischen Fragen geht es um fehlendes Know-how, schlechte oder unvollständige Daten, rechtliche Vorgaben, interne Widerstände und organisatorische Unsicherheit.
Auch typische KI-Probleme wie Halluzinationen, falsche Ergebnisse oder mangelnde Nachvollziehbarkeit erschweren den produktiven Einsatz.

Siehe auch:
Digitalisierung – Mehr als nur Technik

Die gigantischen BYD-Autofrachter haben Europa erreicht.
Doch Vorsicht! Chinesische Autos sind große Datensammler und damit eine echte Herausforderung für unseren Datenschutz.

Massenüberwachung mit Künstlicher Intelligenz nimmt weltweit zu!
Intelligente Kameras mit Gesichtserkennung sind die Zukunft.

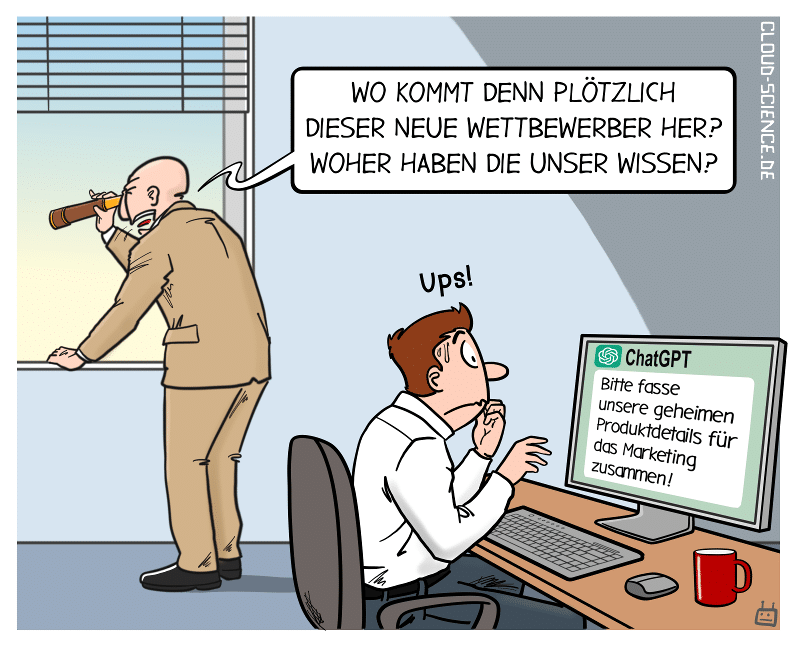
…bleiben besser Betriebsgeheimnisse!
Wenn du ChatGPT mit sensiblen Daten fütterst, kannst du schnell in Schwierigkeiten geraten. Die Daten können von OpenAI verwendet, verkauft oder für eigene Produkte umgesetzt werden. Du weißt nie, wer Zugriff auf deine Daten hat oder was damit passiert.
Es ist wichtig, sicherzustellen, dass du nur relevante und notwendige Informationen teilst und ChatGPT nicht mit vertraulichen oder geschützten Daten fütterst. Sei vorsichtig und bewahre die Kontrolle über deine Daten!
Ransomware-Angriffe nehmen weltweit zu und die Methoden werden immer ausgefuchster. #Ransomware #ITSicherheit #Cybersecurity

